A practitioner's framework for CIOs, CTOs, and data engineering leaders who need to choose a data platform — and need to do it without being sold to.
When a Stock Jumps 37%, Pay Attention to What It's Really Telling You
After Snowflake (SNOW) reported Q1 FY2027 earnings on May 27, 2026, the stock surged roughly 37% — its biggest single-day move in years. By the May 28 open, the market had repriced the company almost entirely around one theme: enterprise AI demand is real, and it is landing on the data platform.
The numbers were hard to dismiss. Product revenue of $1.33 billion, up 34% year-over-year. Net revenue retention at 126% — meaning existing customers are spending significantly more over time. A guidance raise to $5.84 billion for the full fiscal year. A $6 billion multi-year AWS commitment — more than double the prior agreement — built around running AI workloads closer to governed enterprise data on AWS's Arm-based Graviton and AI-accelerated infrastructure. And a tuck-in acquisition (Natoma) to strengthen agentic AI access controls.
Meanwhile, Databricks — still private but valued at $134 billion, with a $5.4 billion revenue run-rate and 65%+ year-over-year growth — is positioning for an expected 2026 IPO.
These are not niche platforms. They are where the enterprise world is placing its data bets.
Here is what the move actually tells you — and the reason this is a DataMy post and not a markets recap: the public market just re-rated a data company almost entirely on the strength of its AI demand. That is the clearest signal yet that in the AI era, the quality of your data foundation is not a backroom IT decision — it is a strategic business asset.
AI initiatives don't fail because the models are bad. They fail because the data feeding them is ungoverned, siloed, poorly modeled, or trapped in a platform that can't serve it to the ML layer without expensive hand-off pipelines. Every enterprise rushing to deploy LLMs, copilots, or autonomous agents is about to discover that their data warehouse — or data lake — is either an accelerant or a bottleneck. The same forces that just added tens of billions to Snowflake's market cap are the ones that will decide whether your AI program ships or stalls.
Which means the platform evaluation decision that most organizations treat as a procurement exercise is actually a foundational strategic call. And it is one that vendors are heavily motivated to influence in their favor — never more so than in a week when one of them is riding a 37% pop and a $6 billion headline.
This article gives you the framework to evaluate these platforms on your terms, not theirs.
The Problem With How Most Evaluations Go Wrong
The standard enterprise platform evaluation follows a familiar script: issue an RFI, attend vendor demos, run a proof of concept with vendor-supplied support engineers, and compare published pricing. The result is predictable — the vendor that invests most in the evaluation wins, not necessarily the platform that fits best.
Three structural biases are almost always present:
Bias 1: The PoC is vendor-tuned. Snowflake and Databricks field teams are expert at designing PoCs that showcase their strengths. Your PoC data is carefully chosen, your queries are optimized by engineers who do this every day, and the performance benchmarks reflect best-case conditions that your team won't replicate in production.
Bias 2: Published pricing is not your pricing. Snowflake credits and Databricks DBUs are opaque by design. The published rate cards don't include your negotiated enterprise discount, the egress charges you'll accumulate moving data between clouds, the support tier you'll need at scale, or the engineering headcount required to run the platform efficiently. Two organizations running similar workloads can have 2–3× cost variance based on how well their teams tune the platform.
Bias 3: The evaluation measures today's workload, not tomorrow's. A warehouse that serves your 2026 BI reports perfectly may be the wrong foundation for the AI agents you plan to deploy in 2027. The platform that wins the PoC for SQL analytics may be the wrong architectural bet for ML model training and real-time feature serving.
A vendor-agnostic evaluation corrects for all three biases. Here's how.
Section 1 — The Eight Evaluation Pillars
A rigorous, vendor-neutral evaluation of any data platform should score across eight dimensions. Each pillar has a set of objective, verifiable questions. Do not accept vendor self-assessment — require documentation or live technical proof.
Pillar 1: Workload Fit
The most important dimension. A platform that excels at one workload class often underperforms on another.
| Workload Type | What to Measure | Best Platform Fit |
|---|---|---|
| Structured SQL analytics, BI, dashboards | Query latency on complex JOINs; concurrency at peak load; materialized view performance | Snowflake, BigQuery |
| ML model training, feature engineering | Python/Spark job performance; GPU cluster efficiency; feature store integration; MLflow compatibility | Databricks |
| Real-time ingestion + streaming analytics | End-to-end latency from Kafka/event source to queryable result; Iceberg write performance under streaming load | Databricks, Confluent + Iceberg |
| Mixed BI + AI (dominant enterprise pattern) | How cleanly the platform handles both SQL dashboards and Python ML pipelines without data duplication or handoff pipelines | Databricks Lakehouse, Snowflake with Cortex ML |
| On-premises or sovereign cloud requirement | Can it run entirely in your datacenter or on a sovereign cloud instance with no data leaving the boundary? | Cloudera, Microsoft Fabric (sovereign regions) |
Evaluation action: Map your actual workload distribution — what percentage of queries are SQL reporting, ML training, streaming, ad hoc, or operational? Score each candidate platform against your specific mix, not an industry average.
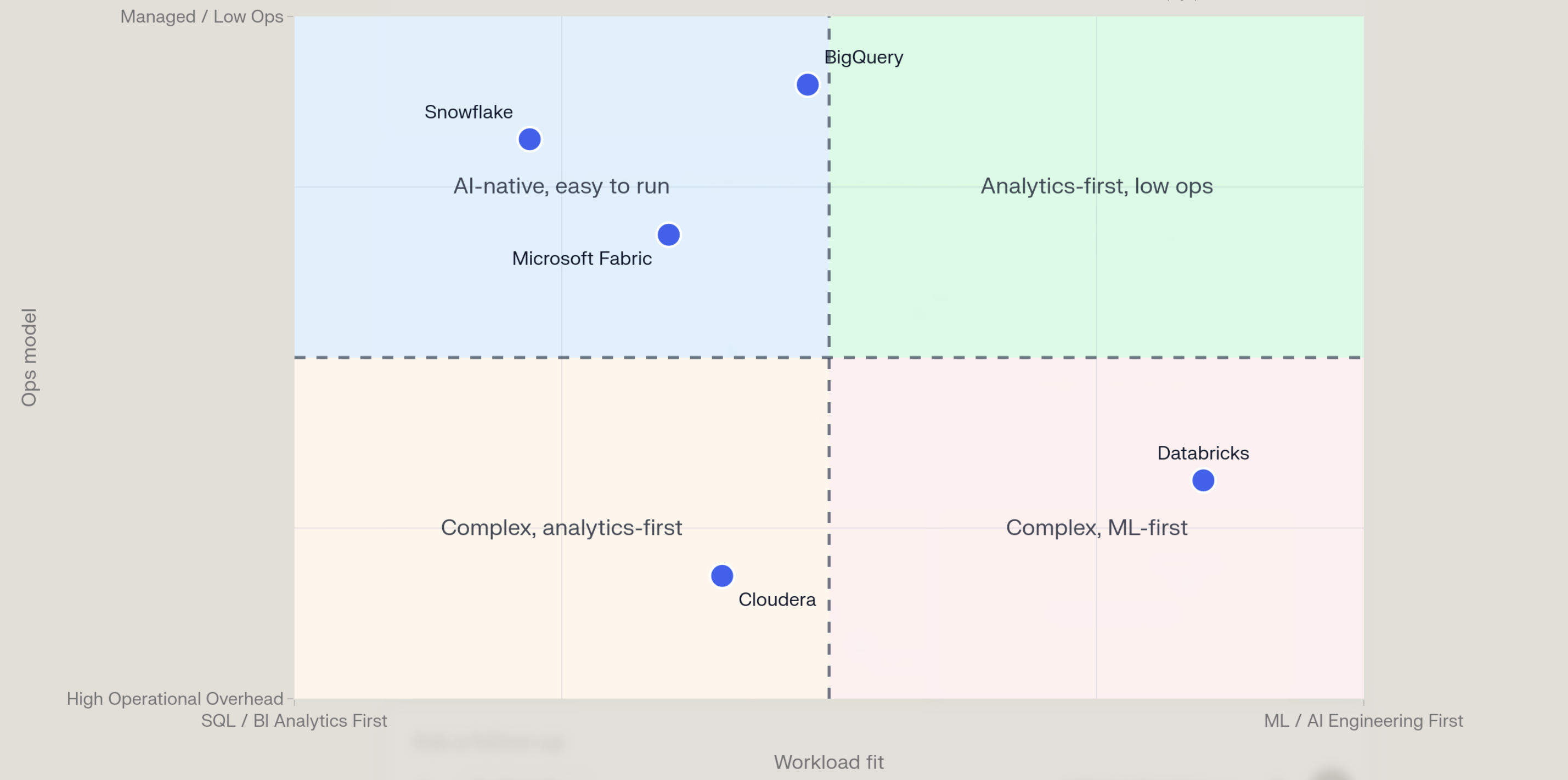
Data Platform Workload Fits vs Operational Overhead
Pillar 2: Total Cost of Ownership — True TCO, Not Rate Card Math
Published pricing is the starting point, not the answer. True TCO for a data platform has five cost layers, and most evaluations only address the first two.
Layer 1: Compute Cost
Snowflake bills in credits — one credit equals one virtual warehouse running for one hour at the smallest unit (XS). Costs scale multiplicatively with warehouse size; an XL warehouse consumes 16× more credits than XS.
Databricks bills in DBUs — Databricks Units — with rates that vary by workload type (SQL, Jobs, ML Runtime), cloud provider (AWS vs Azure vs GCP), and instance type. A Databricks SQL Pro cluster consumes DBUs at a different rate than an ML Runtime cluster on the same underlying VM.
The critical difference: Snowflake auto-suspends idle warehouses and charges nothing for idle time. Databricks clusters require explicit auto-termination configuration — teams without mature cluster management policies routinely accumulate idle cluster costs.
Representative benchmark (mid-market profile, 5TB stored, 200 hours/month of medium-sized analytical compute, 50 hours ML training):
| Platform | Estimated Monthly Compute Cost | Engineering Hours Required |
|---|---|---|
| Snowflake | $3,000–$4,500 | Low — fully managed, auto-tuned |
| Databricks | $1,800–$2,800 | High — requires cluster sizing, tuning, Delta optimization |
| BigQuery | $2,500–$4,000 | Low — serverless auto-scaling |
Note: Databricks' compute is approximately 37% cheaper in raw terms, but this advantage narrows significantly once engineering overhead is factored in.
Layer 2: Storage Cost
All major platforms have decoupled compute and storage. Object storage (S3, ADLS, GCS) runs at roughly $0.02/GB/month regardless of platform.
The divergence is in managed vs. customer-owned storage:
- Snowflake's internal storage (Snowflake's proprietary format) typically costs $23–$40/TB/month
- Snowflake Iceberg Tables on customer-owned S3 costs $0.02/GB/month for storage — but you manage the storage yourself
- Databricks stores data on your object storage by default (Delta Lake or Iceberg on S3/ADLS) — the $0.02/GB rate applies directly
- BigQuery charges $0.02/GB/month for active storage and $0.01/GB for long-term storage
Optimization lever: For organizations with >50TB of managed Snowflake data, migrating to Snowflake Iceberg Tables on customer-owned S3 routinely yields 40–60% storage cost reduction.
Layer 3: Egress Fees
One of the most consistently underestimated cost categories. Every time data leaves a cloud region — to another cloud, to a BI tool hosted differently, or to a downstream system — egress charges apply.
- AWS egress: $0.09/GB
- Azure egress: $0.08/GB
- GCP egress: $0.08/GB
An organization processing 100TB of cross-region data transfers per month pays $8,000–$9,000/month in egress alone — a line item that appears nowhere on most vendor TCO estimates.
Evaluation action: Map your data flows. Identify all cross-region, cross-cloud, and outbound data movements. Multiply by the relevant egress rate for your cloud. This number routinely surprises organizations by $100K+ annually.
Layer 4: Support and Professional Services
Enterprise support tiers for Snowflake and Databricks start at $15,000–$30,000/year for basic coverage and scale to $100,000+/year for 24/7 critical-path support. This cost is often excluded from platform pricing comparisons but is non-negotiable at scale.
Additionally, budget for platform professional services for initial setup, query optimization, and governance configuration: typically $50,000–$200,000 for initial deployment, depending on complexity.
Layer 5: Engineering Headcount and Operational Overhead
This is the largest invisible cost in most TCO models.
| Platform | Team Profile Required | Relative Operational Overhead |
|---|---|---|
| Snowflake | SQL-native analysts + one DBA equivalent for governance and cost management | Low — fully managed; minimal cluster tuning |
| Databricks | Data engineers with Spark/Python expertise; DevOps for cluster management; MLflow administration | Medium-High — requires active cluster optimization and Delta table maintenance |
| BigQuery | Serverless — lowest operational overhead; some cost governance tooling required | Very Low |
| Cloudera | Hadoop/Linux expertise for on-premises; cloud-native skills for CDP | High (on-prem) / Medium (cloud) |
In Singapore and APAC markets, a mid-level data engineer with Databricks Spark expertise commands $80,000–$140,000/year in base salary. A Databricks deployment that requires two additional FTEs over a Snowflake deployment carries $160,000–$280,000/year in hidden TCO before a single query runs.
Full TCO Formula
True Annual TCO =
(Compute credits/DBUs × hourly rate)
+ (Storage GB × $/GB/month × 12)
+ (Egress GB × $/GB)
+ Support contract
+ Professional services
+ (Additional FTE headcount × fully-loaded salary cost)
+ Data quality remediation (budget 20–30% of migration cost)
Build this model in a spreadsheet with your actual workload parameters. Do not let a vendor build it for you.
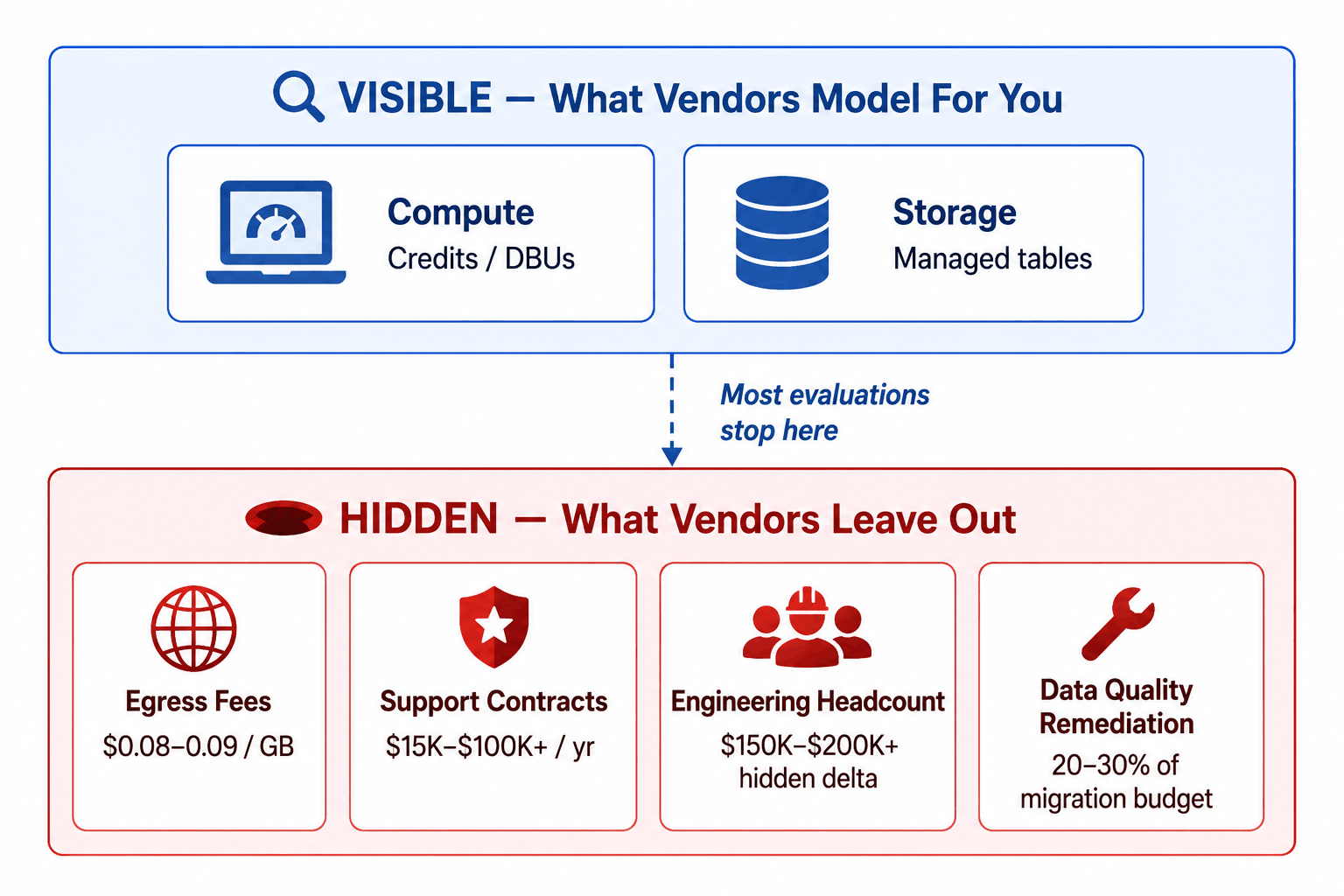
The Visible Cost and Hidden Cost
Pillar 3: Openness and Vendor Lock-In Risk
The data platform you choose today will hold your data for 5–10 years. The switching cost is not just the platform license — it's the migration effort, the rewritten pipelines, and the replatformed governance layer.
Ask every vendor these four questions directly:
- Can I export all my data in Apache Iceberg format without paying additional fees?
- Can a different compute engine (Trino, Spark, Athena) query my data without going through your platform?
- Is your metadata catalog accessible via the open Iceberg REST Catalog API?
- If I decide to stop using your platform, what is the exact process and cost to migrate my data?
The answers reveal how much lock-in risk you are accepting:
| Platform | Iceberg Support | Open Catalog | Lock-In Risk |
|---|---|---|---|
| Snowflake | Native Iceberg Tables; customer-owned storage option | Snowflake Open Catalog (managed Apache Polaris); Iceberg REST API | Low-Medium — Iceberg on your storage gives you a clean exit; proprietary internal format still exists |
| Databricks | Delta Lake + UniForm (write once, read as Iceberg from any engine) | Unity Catalog OSS; Iceberg REST API | Low — Delta + UniForm means data is interoperable; Unity Catalog is open-sourced |
| BigQuery | Iceberg via BigLake / managed Iceberg external tables | BigLake metastore; Iceberg REST API | Medium — proprietary BigQuery storage format still dominant; Google Cloud dependency |
| AWS Redshift | Iceberg via S3 Tables + Redshift Spectrum | AWS Glue Data Catalog (Iceberg REST adapter) | Medium — Iceberg compatibility added but Redshift is AWS-native |
| Cloudera | Native Iceberg (cloud + on-premises) | Open Catalog | Low — strongest hybrid story; open standards throughout |
| Microsoft Fabric | Delta-native + Iceberg serving via OneLake | OneLake catalog | Medium — OneLake is proprietary; Microsoft ecosystem dependency |
Recommendation: Any platform you choose should support Apache Iceberg on customer-owned storage as a first-class option. This is your architectural escape hatch. If a vendor makes Iceberg adoption friction-heavy (complex setup, additional fees, degraded performance), that is a red flag.
Pillar 4: Governance Maturity
Governance is not a feature — it is a prerequisite for AI. AI systems querying ungoverned data produce confident, wrong answers. The governance layer is also where most platform evaluations are weakest, because governance capabilities are hard to demo in a 90-minute session.
Evaluate governance across five dimensions:
| Governance Dimension | What to Test | Leading Platforms |
|---|---|---|
| Data catalog and discovery | Can a new engineer find, understand, and trust a table without asking a colleague? | Snowflake (Search Optimization + Semantic Views), Databricks (Unity Catalog + AI/BI Genie), Alation (third-party, integrates with all platforms) |
| Fine-grained access control | Can you enforce row-level and column-level security without custom views? | All major platforms — but implementation complexity varies significantly |
| Data lineage | Can you trace a dashboard metric back to its source table, transformation, and ingestion job? | Databricks Unity Catalog, Snowflake Access History, OpenLineage-compatible tools |
| Semantic layer | Do metric definitions exist at the platform level — available to both BI tools and AI models? | Snowflake Semantic Views, Databricks AI/BI Genie, dbt MetricFlow (platform-agnostic) |
| Data quality contracts | Are schema and quality guarantees enforced at ingestion — or discovered only when a dashboard breaks? | dbt (platform-agnostic), Monte Carlo, Databricks Delta expectations |
The semantic layer test is the most important for AI readiness. Ask the vendor: "If I ask your platform what 'revenue' means, can it give me a governed, canonical definition that is consistent across every query and every AI model that accesses this data?" If the answer is a demo of natural language SQL generation (not semantic definitions), they have not answered the question.
Pillar 5: AI Readiness
Given the pace of AI adoption in 2026, your data platform is also your AI infrastructure. The diagram below shows why the layers beneath AI matter as much as the AI layer itself — every capability in the table that follows depends on the governance and semantic layers being in place first.
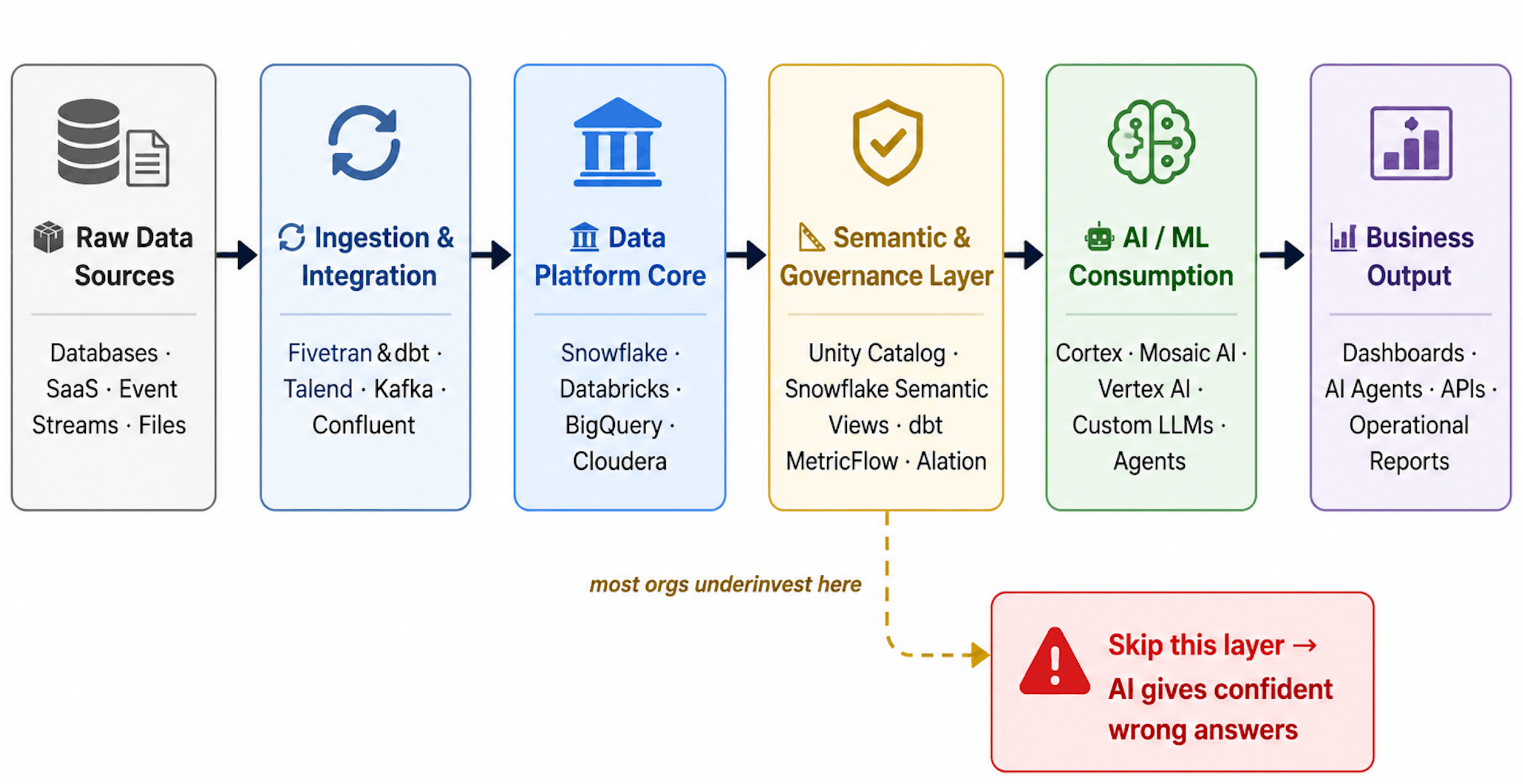
AI Readiness for Data Platform
Evaluate these capabilities:
| AI Capability | What It Enables | Test Question |
|---|---|---|
| Native LLM functions (text-to-SQL, summarization) | Analysts query data in natural language; auto-generated summaries | Ask for a live demo on your actual data schema — not a vendor-prepared dataset |
| Native vector search | RAG patterns, semantic search, similarity matching in-database | Does it work without a separate vector database? What is the query latency at 10M+ vectors? |
| Agentic AI data access (MCP) | AI agents can discover and query data autonomously | Does the platform expose an MCP server endpoint? Can you configure agent access policies? |
| Feature store | ML models have a consistent, governed source of computed features | Does the feature store integrate with the model registry? Can you version features? |
| Model serving / inference | Run inference directly on platform data without exporting it | Latency, throughput, and cost per inference — especially for large models |
2026 state of play:
- Snowflake Cortex covers LLM functions, vector search, and is building toward an agentic control layer with Snowflake Intelligence. The newly expanded AWS deal deepens this — AI workloads running on AWS infrastructure can access Snowflake-governed data without data movement, which is precisely the integration the market rewarded on May 27.
- Databricks Mosaic AI is currently the most complete platform for end-to-end ML: feature engineering, model training, serving, and monitoring in a single lineage-tracked environment. Its AI/BI Genie natural-language layer has seen rapid enterprise adoption.
- BigQuery has the tightest integration with Google Vertex AI and Gemini — the best fit for organizations using Google Cloud for their AI infrastructure.
Pillar 6: Migration Effort and Realistic Timeline
This is the cost that is almost never modeled in pre-selection evaluations and is almost always the primary source of project overruns.
Migration Complexity Tiers
| Migration Scenario | Typical Timeline | Typical Cost Range | Highest Risk Factor |
|---|---|---|---|
| Single-source lift-and-shift (one on-prem warehouse → cloud DW, same schema) | 3–6 months | $200K–$600K | Data quality discovery: 30–40% of budget often spent on fixing issues found during migration, not anticipated before |
| Multi-source warehouse consolidation (3–5 source systems into one governed platform) | 6–12 months | $600K–$1.5M | Schema harmonization and business rule alignment between source systems |
| Legacy + governance rebuild (warehouse migration + new data catalog + RBAC implementation) | 9–18 months | $1M–$2.5M | Organizational change management and data stewardship staffing |
| Full lakehouse transformation (warehouse + lake + ML platform + semantic layer + governance) | 18–30 months | $1.5M–$4M+ | Scope creep; technical debt accumulation mid-project; team turnover |
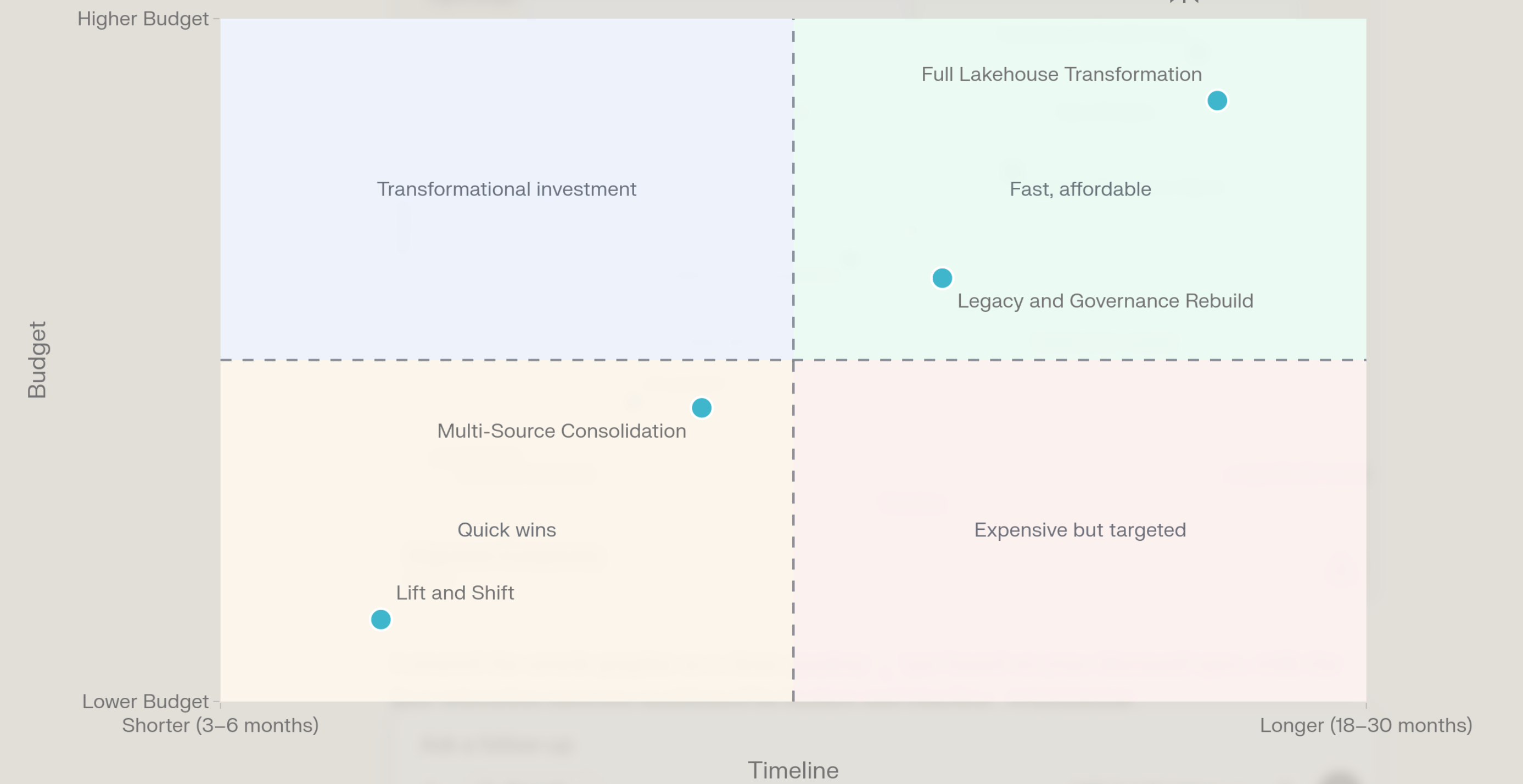
Data Platform Migration Complexity
The 30% Contingency Rule
Budget at least 30% contingency on every data platform migration. The highest-variance cost driver is data quality remediation — issues that only surface when data is actually moved and profiled. A pharma organization that migrated to a cloud lakehouse discovered PII in 40% of its tables post-migration, triggering a retroactive remediation program that cost more than the migration itself.
The Replatform-Without-Redesign Trap
The most common migration failure mode: migrating existing ETL logic verbatim onto the new platform. The result is a faster database running the same unmaintainable transformation complexity. You paid cloud prices to replicate a legacy architecture.
Migrations that deliver ROI redesign the data model and transformation layer in the same motion. This takes longer and costs more upfront — but the total cost of the resulting platform is dramatically lower over a 3-year horizon.
Migration Effort by Platform Target
| Migrating From → To | Relative Effort | Key Migration Challenge |
|---|---|---|
| On-prem Oracle/Teradata → Snowflake | Medium | SQL dialect differences (Teradata BTEQ, Oracle PL/SQL); stored procedure conversion |
| On-prem Hadoop/Hive → Databricks Lakehouse | Medium-High | Spark optimization (not all Hive jobs parallelize cleanly); partition strategy rethink |
| Redshift → Snowflake | Low | SQL compatibility is high; primary effort is ETL tool reconfiguration |
| Snowflake → Databricks | Medium | Data format migration (Snowflake internal → Iceberg/Delta); pipeline rewrite in PySpark |
| Databricks → Snowflake | Low (if using Iceberg) | If data is already in Iceberg format, Snowflake reads it directly; no data movement required |
| Any platform → Iceberg on object storage | Low (storage layer only) | Compute layer reconfiguration required separately |
Pillar 7: Vendor Financial Health and Roadmap Stability
Vendor selection is a 5–10 year commitment. Evaluating a vendor's current features without assessing their financial trajectory is incomplete due diligence.
| Vendor | 2026 Financial Status | Key Roadmap Signal |
|---|---|---|
| Snowflake | FY2027 Q1: $1.33B product revenue (+34% YoY); guidance raised to $5.84B for FY2027; $6B AWS commitment; 126% net revenue retention; stock +~37% on the print | Doubling down on the AI Data Cloud: Cortex, Semantic Views, Snowflake Intelligence as an agentic layer; deepened AWS partnership for AI inference; Natoma acquisition for agent access control |
| Databricks | $5.4B revenue run-rate; 65%+ YoY growth; $134B valuation; IPO expected in 2026 (no S-1 filed yet) | Lakebase (serverless Postgres for AI workloads) targets the warehouse/OLTP silo; Mosaic AI for end-to-end ML; IPO capital would accelerate enterprise sales |
| Google BigQuery | Alphabet (GOOGL) — operationally stable; Google Cloud growing strongly | Deep Vertex AI + Gemini integration; AI-first serverless analytics |
| Cloudera | Private (KKR ownership); long-term hybrid platform commitment | Hybrid lakehouse focus; native Iceberg across cloud and on-prem; on-premises AI inference |
| Microsoft Fabric | Microsoft (MSFT) — strong financial backing; Fabric GA since November 2023 | OneLake as the universal storage layer; deep Copilot and Azure OpenAI integration |
Key observation: Snowflake's Q1 FY2027 performance and the expanded AWS deal directly challenge a narrative that had been building in analyst circles — that Databricks was "winning" and Snowflake was plateauing. A 34% product revenue acceleration and 126% net revenue retention suggest the opposite: enterprise AI workloads are expanding onto Snowflake, not away from it. The market is not converging on a single winner — it is bifurcating between the governance-first (Snowflake) and engineering-first (Databricks) camps, with most large enterprises running both.
Pillar 8: Data Sovereignty and Compliance
For organizations operating in Singapore, other APAC markets, or regulated industries, data residency is not a feature request — it is a hard constraint.
| Compliance Requirement | Platform Options |
|---|---|
| Data cannot leave Singapore | All major cloud platforms have Singapore-region availability (Snowflake on AWS ap-southeast-1, Databricks on AWS/Azure Singapore) |
| Data cannot leave the building (on-prem sovereign cloud) | Cloudera only — the sole enterprise lakehouse platform supporting full on-prem deployment including native Iceberg |
| MAS TRM compliance (Singapore FSI) | All cloud platforms support — but architecture must be documented; data classification, access logging, and key management must be configured |
| PDPA Singapore / GDPR | Requires column-level masking, audit trails, and right-to-erasure support — available in Snowflake, Databricks, and BigQuery; requires explicit configuration |
Section 2 — Red Flags in Vendor Sales Conversations
When a vendor says one of the following, probe further before accepting the claim:
"Our platform is the most cost-effective." Cost-effective for what workload, at what scale, with what team profile? Demand a TCO model built with your specific data volumes, query patterns, and headcount constraints — not a generic benchmark.
"Our PoC will prove the performance." A PoC run by the vendor's field engineering team with vendor-curated data proves vendor engineering quality, not your team's operational reality. Require a PoC run by your own engineers, on your own representative data, without vendor-side optimization assistance.
"Migrating away from our platform is simple." Ask for a documented migration guide, a list of migration projects they have supported to other platforms, and a contractual data portability guarantee. Vendors that make exit easy are the ones you can trust.
"Governance is built in." Every vendor says this. Ask specifically: Does your catalog enforce row-level security natively? Can I see data lineage from source to dashboard without a third-party tool? Can AI agents be assigned data access policies? The gap between "governance features exist" and "governance is operationalized" is where most implementations fail.
"One platform for everything." No platform is best for every workload. If a vendor is actively discouraging you from using a second platform for workloads that are not their strength, that is a red flag about their incentives — not your architecture.
Section 3 — The Evaluation Scorecard
Use this scorecard to structure your evaluation. Score each platform 1–5 for each pillar, weighted by your organization's priorities.
| Evaluation Pillar | Weight (Suggested) | Snowflake | Databricks | BigQuery | Cloudera | Your Score |
|---|---|---|---|---|---|---|
| Workload fit (SQL analytics) | High for BI-heavy | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | |
| Workload fit (ML/AI engineering) | High for ML-heavy | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | |
| True TCO (compute + storage + headcount) | Always high | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | |
| Openness (Iceberg, exit path) | High for long-term | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | |
| Governance maturity | High for regulated | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | |
| AI readiness | High for AI-first | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | |
| Migration effort (from your current stack) | Varies | Varies | Varies | Varies | Varies | |
| Vendor stability | Always relevant | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | |
| Data sovereignty | Critical for regulated | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Fill in the "Your Score" column after conducting live technical testing against each criterion. Aggregate by your organization's pillar weights.
Section 4 — Decision Archetypes From the Field
Based on real enterprise patterns, these are the evaluation outcomes that consistently make sense:
| Organization Profile | Recommended Primary Platform | Recommended Complement | Rationale |
|---|---|---|---|
| FSI / healthcare, governance-heavy, BI-first | Snowflake | dbt + Alation for semantic/governance layer | Strongest governance, RBAC, and audit controls; SQL-native team adoption is fast |
| Tech company, ML-first, Python-native engineering team | Databricks | Snowflake for executive BI layer | Best ML/AI platform; Snowflake for governed dashboards that stakeholders won't tolerate latency on |
| Google Cloud native, analytics + Vertex AI | BigQuery | Vertex AI Pipelines for ML | Zero-friction integration; serverless removes capacity planning; Gemini/Vertex for AI |
| Heavily regulated, data cannot leave on-prem | Cloudera | Snowflake (cloud overlay where permitted) | Only enterprise option for full on-prem lakehouse with native Iceberg |
| Microsoft Azure enterprise, existing M365 investment | Microsoft Fabric | Databricks for ML workloads | OneLake + Power BI integration is unmatched for Microsoft shops; Databricks for ML where Fabric falls short |
| Greenfield, SME, limited data engineering team | Snowflake or BigQuery | dbt Cloud for transformations | Managed simplicity; minimal operational overhead; SQL-accessible for small teams |
| Multi-cloud, heterogeneous legacy estate | Apache Iceberg on object storage + Snowflake SQL + Databricks ML | Denodo for federated access across legacy sources | Architecture that doesn't require full migration; data stays where it is, governed centrally |
Conclusion: The Evaluation Is a Strategy Decision
Snowflake's ~37% stock surge and the $6 billion AWS deal are not just financial headlines. They are market confirmation that enterprise data platforms have become AI infrastructure — and that organizations treating their data platform as a commodity procurement are falling behind those that treat it as a strategic capability.
The stakes of getting the evaluation wrong have never been higher:
- Choose a platform that can't serve your AI workloads → your AI initiatives stall waiting for data pipelines
- Accumulate proprietary format lock-in → a future migration costs $500K–$3M and takes 12–18 months
- Accept a vendor's TCO model at face value → overpay by $300K–$1M annually once egress, headcount, and support are factored in
- Run a vendor-tuned PoC → select a platform optimized for a benchmark, not your actual production workload
The eight-pillar framework above is designed to ensure your evaluation surfaces the real trade-offs. Most organizations will not emerge from it with a single platform — they will emerge with an architecture where the right platform serves the right workload, connected through open standards (Apache Iceberg, Iceberg REST Catalog) that preserve their flexibility to evolve.
That is not vendor indecision. That is sound architecture.
Work With DataMy: Independent Platform Evaluation
What we offer:
- Platform Selection Advisory — an independent evaluation across the eight pillars above, using your actual workload data and team profile. Includes a scored vendor scorecard, TCO model built with your real parameters, and a recommended architecture with migration phasing
- TCO Audit — a deep-dive cost analysis of your current platform spend, with optimization recommendations and comparison against alternative platform configurations
- Migration Planning — pre-migration assessment, scope definition, risk quantification, and phased roadmap for any combination of source-to-target platforms
- Vendor-Neutral PoC Design — we design and run your PoC without vendor involvement, using representative production data and realistic query patterns
Relevant for you if:
- Your current platform costs are growing faster than your data volumes or query counts
- You are planning a cloud data platform migration and need realistic effort and cost estimates
- Your business needs data sovereignty guidance
Contact us: [email protected] Website: datamy.co
References
- Snowflake Stock Jumps 37% After Q1 FY2027 Earnings, AWS Deal — IndMoney
- Snowflake Explodes 37% on $6 Billion Amazon Deal — Yahoo Finance / 24/7 Wall St.
- Snowflake skyrockets after Q1 report features Natoma acquisition and AWS deal — Seeking Alpha
- Snowflake Stock Surges 36% After Q1 2027 Earnings Beat — TIKR
- Databricks Grows >65% YoY, Surpasses $5.4B Revenue Run-Rate — Databricks Newsroom
- Databricks raises $4B at $134B valuation — TechCrunch
- Databricks vs. Snowflake TCO — CTO's Guide (Dateonic)
- Snowflake vs Databricks vs BigQuery: 2026 Pricing Guide (Revefi)
- Data Platform Migration Cost Framework — LatentView
- Snowflake to Databricks Migration Guide — KPI Partners / Medium
- Data Warehouse TCO Guide — MotherDuck